A Bayesian modelling framework for health care resource use and costs in trial-based economic evaluations
Introduction
Building on the existent literature, we propose a novel Bayesian framework for the modelling of HRU data in trial-based economic evaluations, which allows a flexible model specification and the handling of missing data at HRU level. The choice of a Bayesian approach provides practical advantages compared to a standard frequentist framework, including: 1) use of a modular structure to increase model complexity in a relatively easy way; 2) natural interpretation of cost-effectiveness results in probabilistic terms; 3) direct implementation of Probabilistic Sensitivity Analysis (PSA), consisting in the quantification of the impact of parameters’ uncertainty on the economic conclusions. We show the benefits of using our framework on a real case study, with a focus on appropriately modelling partially-observed HRU values and its implications in terms of inferences and, crucially, cost-effectiveness results.
Modelling Framework
We first present our modelling framework building upon previously-introduced approaches, starting at the level of total costs and QALYs or costs and utilities at different times22;23, and then extend these to account for partially-observed HRU data. The framework allows for typical features of cost-effectiveness data (e.g. skewness, correlation, structural values) while also handling missing HRU data without the need to rely on ad-hoc assumptions (e.g. assumed zeros).
The framework allows the modelling of different types of variables, namely HRU and HrQol data, costs and utilities at each time, and total costs and QALYs. From a modelling perspective, it is often desirable to focus at the most aggregated level (e.g. cross-sectional modelling instead of longitudinal). However, in reality, the occurrence of missing values at the most disaggregated level (i.e. HRU and HrQol) is unavoidable, with proportions of unobserved values which are usually substantial5;6. This introduces the problem that individual-level cost values may not be computed and, when item non-response occurs, modelling at aggregated levels may result in considerable loss of information
Figure 1 shows the joint outcomes distribution, expressed in terms of a conditional distributions for utilities, non-zero and structural zero HRUs at time \(j\) given outcomes at time \(j−1\), respectively indicated with a blue, red and green line. The parameters indexing the corresponding distributions or “modules” are indicated with different Greek letters, while \(i\) and \(j\) denote the individual and time index. The black, magenta and green solid arrows show the dependence relationships between the parameters within and between the models and between times, respectively. The dashed arrows denote deterministic relationships.
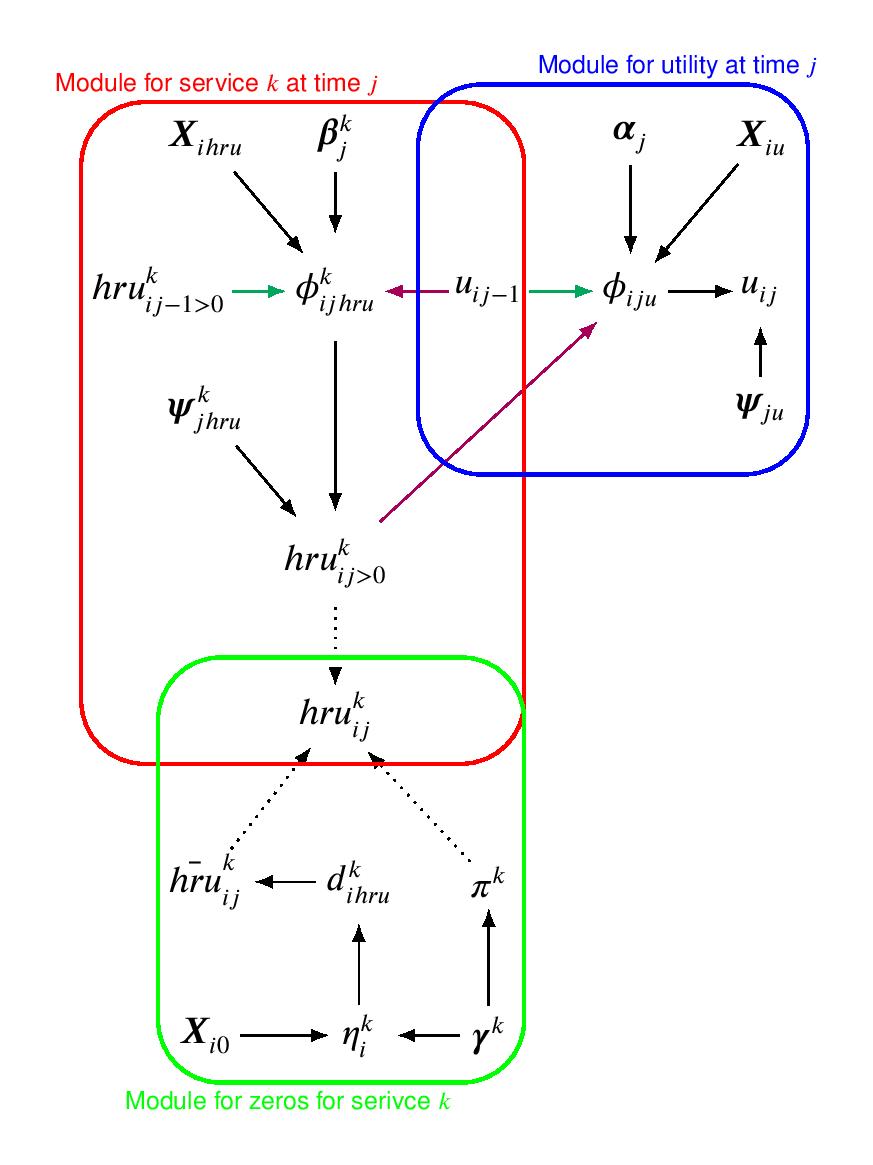
The proposed framework more challenging to implement compared to the modelling of QALYs/Total costs and utilities/costs due to multiple HRU variables, each consisting in a two-part mixture for the non-zero and structural zero components. However, by defining the model at the most disaggregated level, the framework provides the most efficient way to handle partially-observed HRUs. This may become a considerable advantage when applied to questionnaire data affected by item non-response and outweigh the additional complexity required to fit these models.
Conclusions
We have presented a general modelling framework to handle item-level HRU missingness without requiring any ah-hoc imputation. The framework takes advantage of the Bayesian setting to handle different features of the data while also directly quantifying the impact of missingness uncertainty on cost-effectiveness results. Our approach represents an improvement with respect to the current practice and can be implemented in a relatively easy way using freely available software.